
Frequência de letras - Letter frequency
| Carta | Frequência relativa no idioma inglês | |||
|---|---|---|---|---|
| Texto:% s | Dicionários | |||
| UMA | 8,2% |
|
7,8% |
|
| B | 1,5% |
|
2% |
|
| C | 2,8% |
|
4% |
|
| D | 4,3% |
|
3,8% |
|
| E | 13% |
|
11% |
|
| F | 2,2% |
|
1,4% |
|
| G | 2% |
|
3% |
|
| H | 6,1% |
|
2,3% |
|
| eu | 7% |
|
8,6% |
|
| J | 0,15% |
|
0,21% |
|
| K | 0,77% |
|
0,97% |
|
| eu | 4% |
|
5,3% |
|
| M | 2,4% |
|
2,7% |
|
| N | 6,7% |
|
7,2% |
|
| O | 7,5% |
|
6,1% |
|
| P | 1,9% |
|
2,8% |
|
| Q | 0,095% |
|
0,19% |
|
| R | 6% |
|
7,3% |
|
| S | 6,3% |
|
8,7% |
|
| T | 9,1% |
|
6,7% |
|
| você | 2,8% |
|
3,3% |
|
| V | 0,98% |
|
1% |
|
| C | 2,4% |
|
0,91% |
|
| X | 0,15% |
|
0,27% |
|
| Y | 2% |
|
1,6% |
|
| Z | 0,074% |
|
0,44% |
|
A frequência das letras é o número de vezes que as letras do alfabeto aparecem, em média, na linguagem escrita. A análise de frequência de letras remonta ao matemático árabe Al-Kindi (c. 801–873 DC), que desenvolveu formalmente o método para quebrar cifras. A análise da frequência das letras ganhou importância na Europa com o desenvolvimento dos tipos móveis em 1450 DC, onde se deve estimar a quantidade de tipos necessária para cada forma de letra. Os lingüistas usam a análise da frequência das letras como uma técnica rudimentar para identificação da linguagem , onde é particularmente eficaz como uma indicação se um sistema de escrita desconhecido é alfabético, silábico ou ideográfico.
O uso de frequências de letras e análise de frequência desempenha um papel fundamental em criptogramas e vários jogos de quebra-cabeça de palavras, incluindo Hangman , Scrabble e o game show de televisão Wheel of Fortune . Uma das primeiras descrições na literatura clássica de aplicar o conhecimento da frequência das letras em inglês para resolver um criptograma é encontrada na famosa história de Edgar Allan Poe , The Gold-Bug , onde o método é aplicado com sucesso para decifrar uma mensagem dando a localização de um tesouro escondido pelo Capitão Kidd .
As frequências das letras também têm um forte efeito no design de alguns layouts de teclado . As letras mais frequentes estão na linha inferior da máquina de escrever Blickensderfer e na linha inicial do layout do teclado Dvorak .
Fundo

A frequência das letras no texto foi estudada para uso em criptanálise , e análise de frequência em particular, datando do matemático árabe Al-Kindi (c. 801–873 DC), que desenvolveu formalmente o método (as cifras quebráveis por esta técnica volte pelo menos para a cifra de César inventada por Júlio César , então esse método poderia ter sido explorado nos tempos clássicos). A análise da frequência das letras ganhou importância adicional na Europa com o desenvolvimento dos tipos móveis em 1450 dC, onde se deve estimar a quantidade de tipo necessária para cada forma de letra, conforme evidenciado pelas variações no tamanho do compartimento da letra nos casos de tipos de tipógrafos.
Nenhuma distribuição exata de frequência de letras está subjacente a um determinado idioma, uma vez que todos os escritores escrevem de maneira ligeiramente diferente. No entanto, a maioria dos idiomas tem uma distribuição característica que é fortemente aparente em textos mais longos. Mesmo mudanças de linguagem tão extremas como do inglês antigo para o inglês moderno (consideradas mutuamente ininteligíveis) mostram fortes tendências nas frequências das letras relacionadas: em uma pequena amostra de passagens bíblicas, da mais frequente para a menos frequente, enaid sorhm tgþlwu æcfy ðbpxz do inglês antigo compara to eotha sinrd luymw fgcbp kvjqxz do inglês moderno, com as diferenças mais extremas em relação às formas das letras não compartilhadas.
As máquinas de linótipo para a língua inglesa assumiram que a ordem das letras, da mais para a menos comum, era etaoin shrdlu cmfwyp vbgkjq xz com base na experiência e no costume de compositores manuais. O equivalente para a língua francesa era elaoin sdrétu cmfhyp vbgwqj xz .
Organizar o alfabeto em Morse em grupos de letras que requerem períodos iguais de tempo para serem transmitidos e, em seguida, classificar esses grupos em ordem crescente resulta em e it san hurdm wgvlfbk opxcz jyq . A frequência das letras era usada por outros sistemas telegráficos, como o Código Murray .
Idéias semelhantes são usadas em técnicas modernas de compressão de dados , como a codificação de Huffman .
As frequências das letras, como as das palavras , tendem a variar, tanto por escritor quanto por assunto. Não se pode escrever um ensaio sobre raios X sem usar Xs frequentes, e o ensaio terá uma frequência de letras idiossincrática se o ensaio for sobre o uso de raios X para tratar zebras no Qatar. Diferentes autores têm hábitos que podem se refletir no uso das letras. O estilo de escrita de Hemingway , por exemplo, é visivelmente diferente do de Faulkner . Letra, bigrama , trigrama , frequência de palavra, comprimento de palavra e comprimento de frase podem ser calculados para autores específicos e usados para provar ou refutar a autoria de textos, mesmo para autores cujos estilos não sejam tão divergentes.
As frequências médias precisas das letras só podem ser obtidas analisando uma grande quantidade de texto representativo. Com a disponibilidade de computação moderna e coleções de grandes corpora de texto , esses cálculos são facilmente feitos. Os exemplos podem ser extraídos de uma variedade de fontes (reportagens da imprensa, textos religiosos, textos científicos e ficção geral) e há diferenças especialmente para a ficção geral com a posição de 'h' e 'i', com 'h' se tornando mais comum.
Herbert S. Zim , em seu clássico texto introdutório de criptografia "Codes and Secret Writing", dá a sequência de frequência de letras em inglês como "ETAON RISHD LFCMU GYPWB VKJXZQ", os pares de letras mais comuns como "TH HE AN RE ER EM NO AT ND ST ES EN OF TE ED OU TI HI AS TO ", e as letras duplicadas mais comuns como" LL EE SS OO TT FF RR NN PP CC ".
Além disso, observe que diferentes dialetos de um idioma também afetarão a freqüência de uma letra. Por exemplo, um autor nos Estados Unidos produziria algo em que a letra 'z' é mais comum do que um autor no Reino Unido escrevendo sobre o mesmo tópico: palavras como "analisar", "desculpar-se" e "reconhecer" contêm a letra em inglês americano, enquanto as mesmas palavras são escritas "analisar", "apologize" e "reconhecer" em inglês britânico. Isso afetaria muito a frequência da letra 'z', pois é uma letra raramente usada por falantes britânicos no idioma inglês.
As "doze primeiras" letras constituem cerca de 80% do uso total. As "oito primeiras" letras constituem cerca de 65% do uso total. A frequência das letras em função da classificação pode ser bem ajustada por várias funções de classificação, sendo a função de classificação Cocho / Beta de dois parâmetros a melhor. Outra função de classificação sem parâmetro livre ajustável também se ajusta à distribuição de frequência de letras razoavelmente bem (a mesma função foi usada para ajustar a frequência de aminoácidos em sequências de proteínas). Um espião usando a cifra VIC ou alguma outra cifra baseada em um tabuleiro de damas normalmente usa um mnemônico como "pecado para errar" (descartando o segundo "r") ou "em um senhor" para lembrar os oito caracteres principais.
Frequências relativas de letras na língua inglesa

Existem três maneiras de contar a frequência das letras que resultam em gráficos muito diferentes para letras comuns. O primeiro método, usado no gráfico abaixo, é contar a frequência das letras nas palavras raiz de um dicionário. A segunda é incluir todas as variantes de palavras durante a contagem, como "abstracts", "abstracting" e "abstracting" e não apenas a palavra raiz de "abstract". Esse sistema faz com que letras como 's' apareçam com muito mais frequência, como ao contar letras de listas das palavras em inglês mais usadas na Internet. Uma variante final é contar as letras com base na frequência de uso em textos reais, resultando em certas combinações de letras como 'th' se tornando mais comuns devido ao uso frequente de palavras comuns como "o", "então", "ambos", Etc. Medidas de frequência de uso absoluta como esta são usadas ao criar layouts de teclado ou frequências de letras em impressoras antigas.
Uma análise das entradas no dicionário Concise Oxford, ignorando a frequência de uso das palavras, fornece uma ordem de "EARIOTNSLCUDPMHGBFYWKVXZJQ".
A tabela de frequência de letras abaixo foi retirada do site de Pavel Mička, que cita a Matemática Criptológica de Robert Lewand .
De acordo com Lewand, organizadas da mais para menos comum na aparência, as letras são: etaoinshrdlcumwfgypbvkjxqz . A ordenação de Lewand difere ligeiramente de outras, como o Projeto do Explorador de Matemática da Cornell University, que produziu uma tabela após medir 40.000 palavras.
Em inglês, o espaço é ligeiramente mais frequente do que a letra superior (e) e os caracteres não alfabéticos (dígitos, pontuação, etc.) ocupam coletivamente a quarta posição (já tendo incluído o espaço) entre t e a .
Frequências relativas das primeiras letras de uma palavra na língua inglesa
| Carta | Frequência relativa como a primeira letra de uma palavra em inglês | |||
|---|---|---|---|---|
| Texto:% s | Dicionários | |||
| UMA | 1,7% |
|
5,7% |
|
| B | 4,4% |
|
6% |
|
| C | 5,2% |
|
9,4% |
|
| D | 3,2% |
|
6,1% |
|
| E | 2,8% |
|
3,9% |
|
| F | 4% |
|
4,1% |
|
| G | 1,6% |
|
3,3% |
|
| H | 4,2% |
|
3,7% |
|
| eu | 7,3% |
|
3,9% |
|
| J | 0,51% |
|
1,1% |
|
| K | 0,86% |
|
1% |
|
| eu | 2,4% |
|
3,1% |
|
| M | 3,8% |
|
5,6% |
|
| N | 2,3% |
|
2,2% |
|
| O | 7,6% |
|
2,5% |
|
| P | 4,3% |
|
7,7% |
|
| Q | 0,22% |
|
0,49% |
|
| R | 2,8% |
|
6% |
|
| S | 6,7% |
|
11% |
|
| T | 16% |
|
5% |
|
| você | 1,2% |
|
2,9% |
|
| V | 0,82% |
|
1,5% |
|
| C | 5,5% |
|
2,7% |
|
| X | 0,045% |
|
0,05% |
|
| Y | 0,76% |
|
0,36% |
|
| Z | 0,045% |
|
0,24% |
|
A frequência das primeiras letras de palavras ou nomes é útil na pré-atribuição de espaço em arquivos físicos e índices. Dadas 26 gavetas de arquivo , em vez de uma atribuição 1: 1 de uma gaveta a uma letra do alfabeto, muitas vezes é útil usar um código de letras de frequência mais igual, atribuindo várias letras de baixa frequência à mesma gaveta (frequentemente uma gaveta é identificada como VWXYZ) e para dividir as letras iniciais mais frequentes ('S', 'A' e 'C') em várias gavetas (geralmente 6 gavetas Aa-An, Ao-Az, Ca-Cj, Ck-Cz, Sa-Si, Sj-Sz). O mesmo sistema é usado em algumas obras de vários volumes, como algumas enciclopédias . Números de corte , outro mapeamento de nomes para um código de frequência mais igual, são usados em algumas bibliotecas.
Tanto a distribuição geral de letras quanto a distribuição de letras iniciais de palavras correspondem aproximadamente à distribuição Zipf e ainda mais semelhantes à distribuição de Yule .
Freqüentemente, a distribuição de frequência do primeiro dígito em cada dado é significativamente diferente da frequência geral de todos os dígitos em um conjunto de dados numéricos, consulte a lei de Benford para obter detalhes.
Uma análise de Peter Norvig nos dados do Google Books determinou, entre outras coisas, a frequência das primeiras letras das palavras em inglês.
Uma análise de junho de 2012 usando um documento de texto contendo todas as palavras no idioma inglês exatamente uma vez, descobriu que 'S' é a letra inicial mais comum para palavras no idioma inglês, seguida por 'P', 'C' e 'A' .
Frequências relativas de letras em outros idiomas
| Carta | inglês | francês | alemão | espanhol | português | esperanto | italiano | turco | sueco | polonês | holandês | dinamarquês | islandês | finlandês | Tcheco |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| uma | 8,167% | 7,636% | 6,516% | 11,525% | 14,634% | 12,117% | 11,745% | 11,920% | 9,383% | 8,910% | 7,486% | 6,025% | 10,110% | 12,217% | 8,421% |
| b | 1,492% | 0,901% | 1,886% | 2,215% | 1.043% | 0,980% | 0,927% | 2,844% | 1,535% | 1,470% | 1,584% | 2.000% | 1.043% | 0,281% | 0,822% |
| c | 2,782% | 3.260% | 2,732% | 4,019% | 3,882% | 0,776% | 4,501% | 0,963% | 1,486% | 3,960% | 1,242% | 0,565% | 0 | 0,281% | 0,740% |
| d | 4,253% | 3,669% | 5,076% | 5,010% | 4,992% | 3,044% | 3,736% | 4,706% | 4,702% | 3,250% | 5,933% | 5,858% | 1,575% | 1.043% | 3,475% |
| e | 12,702% | 14,715% | 16,396% | 12,181% | 12,570% | 8,995% | 11,792% | 8,912% | 10,149% | 7,660% | 18,91% | 15,453% | 6,418% | 7,968% | 7,562% |
| f | 2,228% | 1.066% | 1,656% | 0,692% | 1,023% | 1,037% | 1,153% | 0,461% | 2,027% | 0,300% | 0,805% | 2,406% | 3,013% | 0,194% | 0,084% |
| g | 2,015% | 0,866% | 3,009% | 1,768% | 1,303% | 1,171% | 1,644% | 1,253% | 2,862% | 1,420% | 3,403% | 4,077% | 4,241% | 0,392% | 0,092% |
| h | 6,094% | 0,737% | 4.577% | 0,703% | 0,781% | 0,384% | 0,636% | 1,212% | 2,090% | 1,080% | 2,380% | 1,621% | 1.871% | 1,851% | 1,356% |
| eu | 6,966% | 7,529% | 6,550% | 6,247% | 6,186% | 10,012% | 10,143% | 8,600% * | 5,817% | 8,210% | 6,499% | 6,000% | 7,578% | 10,817% | 6,073% |
| j | 0,153% | 0,613% | 0,268% | 0,493% | 0,397% | 3,501% | 0,011% | 0,034% | 0,614% | 2,280% | 1,46% | 0,730% | 1,144% | 2,042% | 1,433% |
| k | 0,772% | 0,074% | 1,417% | 0,011% | 0,015% | 4,163% | 0,009% | 4,683% | 3,140% | 3,510% | 2,248% | 3,395% | 3,314% | 4,973% | 2,894% |
| eu | 4,025% | 5,456% | 3,437% | 4,967% | 2,779% | 6,104% | 6,510% | 5,922% | 5,275% | 2.100% | 3,568% | 5,229% | 4.532% | 5,761% | 3,802% |
| m | 2,406% | 2,968% | 2,534% | 3,157% | 4.738% | 2,994% | 2,512% | 3,752% | 3,471% | 2.800% | 2,213% | 3,237% | 4,041% | 3,202% | 2,446% |
| n | 6,749% | 7,095% | 9,776% | 6,712% | 4,446% | 7,955% | 6,883% | 7,487% | 8,542% | 5,520% | 10,032% | 7,240% | 7,711% | 8,826% | 6,468% |
| o | 7,507% | 5,796% | 2,594% | 8,683% | 9,735% | 8,779% | 9,832% | 2,476% | 4,482% | 7,750% | 6,063% | 4,636% | 2,166% | 5,614% | 6,695% |
| p | 1,929% | 2,521% | 0,670% | 2,510% | 2,523% | 2,755% | 3,056% | 0,886% | 1.839% | 3,130% | 1,57% | 1,756% | 0,789% | 1,842% | 1,906% |
| q | 0,095% | 1,362% | 0,018% | 0,877% | 1,204% | 0 | 0,505% | 0 | 0,020% | 0,140% | 0,009% | 0,007% | 0 | 0,013% | 0,001% |
| r | 5,987% | 6,693% | 7,003% | 6,871% | 6,530% | 5,914% | 6,367% | 6,722% | 8,431% | 4,690% | 6,411% | 8,956% | 8,581% | 2,872% | 4,799% |
| s | 6,327% | 7,948% | 7,270% | 7,977% | 6,805% | 6,092% | 4,981% | 3,014% | 6,590% | 4.320% | 3,73% | 5,805% | 5,630% | 7,862% | 5,212% |
| t | 9,056% | 7,244% | 6,154% | 4,632% | 4,336% | 5,276% | 5,623% | 3,314% | 7,691% | 3,980% | 6,79% | 6,862% | 4,953% | 8,750% | 5,727% |
| você | 2,758% | 6,311% | 4,166% | 2,927% | 3,639% | 3,183% | 3,011% | 3,235% | 1,919% | 2.500% | 1,99% | 1,979% | 4.562% | 5,008% | 2,160% |
| v | 0,978% | 1.838% | 0,846% | 1,138% | 1,575% | 1,904% | 2,097% | 0,959% | 2,415% | 0,040% | 2,85% | 2,332% | 2,437% | 2,250% | 5,344% |
| C | 2,360% | 0,049% | 1,921% | 0,017% | 0,037% | 0 | 0,033% | 0 | 0,142% | 4,650% | 1,52% | 0,069% | 0 | 0,094% | 0,016% |
| x | 0,150% | 0,427% | 0,034% | 0,215% | 0,253% | 0 | 0,003% | 0 | 0,159% | 0,020% | 0,036% | 0,028% | 0,046% | 0,031% | 0,027% |
| y | 1,974% | 0,128% | 0,039% | 1,008% | 0,006% | 0 | 0,020% | 3,336% | 0,708% | 3,760% | 0,035% | 0,698% | 0,900% | 1,745% | 1.043% |
| z | 0,074% | 0,326% | 1,134% | 0,467% | 0,470% | 0,494% | 1,181% | 1.500% | 0,070% | 5,640% | 1,39% | 0,034% | 0 | 0,051% | 1,599% |
| uma | ~ 0% | 0,486% | 0 | 0 | 0,072% | 0 | 0,635% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| uma | ~ 0% | 0,051% | 0 | 0 | 0,562% | 0 | ~ 0% | ~ 0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| uma | 0 | 0 | 0 | 0,502% | 0,118% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,799% | 0 | 0,867% |
| uma | ~ 0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,338% | 0 | 0 | 1,190% | 0 | 0,003% | 0 |
| uma | 0 | 0 | 0,578% | 0 | 0 | 0 | 0 | 0 | 1,797% | 0 | 0 | 0 | 0 | 3,577% | 0 |
| uma | 0 | 0 | 0 | 0 | 0,733% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| uma | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,990% | 0 | 0 | 0 | 0 | 0 |
| æ | ~ 0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,872% | 0,867% | 0 | 0 |
| œ | ~ 0% | 0,018% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ç | ~ 0% | 0,085% | 0 | 0 | 0,530% | 0 | 0 | 1,156% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ĉ | 0 | 0 | 0 | 0 | 0 | 0,657% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ć | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,400% | 0 | 0 | 0 | 0 | 0 |
| č | ~ 0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,462% |
| ď | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,015% |
| ð | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4,393% | 0 | 0 |
| è | ~ 0% | 0,271% | 0 | 0 | 0 | 0 | 0,263% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| é | ~ 0% | 1,504% | 0 | 0,433% | 0,337% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,647% | 0 | 0,633% |
| ê | 0 | 0,218% | 0 | 0 | 0,450% | 0 | ~ 0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ë | ~ 0% | 0,008% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| é | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,110% | 0 | 0 | 0 | 0 | 0 |
| ě | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,222% |
| ĝ | 0 | 0 | 0 | 0 | 0 | 0,691% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ğ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,125% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ĥ | 0 | 0 | 0 | 0 | 0 | 0,022% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| eu | 0 | 0,045% | 0 | 0 | 0 | 0 | ~ 0% | ~ 0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| eu | 0 | 0 | 0 | 0 | 0 | 0 | (0,030%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| eu | 0 | 0 | 0 | 0,725% | 0,132% | 0 | 0,030% | 0 | 0 | 0 | 0 | 0 | 1,570% | 0 | 1,643% |
| eu | ~ 0% | 0,005% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| eu | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5,114% * | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ĵ | 0 | 0 | 0 | 0 | 0 | 0,055% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| eu | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.820% | 0 | 0 | 0 | 0 | 0 |
| ñ | ~ 0% | 0 | 0 | 0,311% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ń | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,200% | 0 | 0 | 0 | 0 | 0 |
| ň | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,007% |
| ò | 0 | 0 | 0 | 0 | 0 | 0 | 0,002% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ö | ~ 0% | 0 | 0,443% | 0 | 0 | 0 | 0 | 0,777% | 1,305% | 0 | 0 | 0 | 0,777% | 0,444% | 0 |
| ô | ~ 0% | 0,023% | 0 | 0 | 0,635% | 0 | ~ 0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ó | 0 | 0 | 0 | 0,827% | 0,296% | 0 | ~ 0% | 0 | 0 | 0,850% | 0 | 0 | 0,994% | 0 | 0,024% |
| õ | 0 | 0 | 0 | 0 | 0,040% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ø | ~ 0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,939% | 0 | 0 | 0 |
| ř | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,380% |
| ŝ | 0 | 0 | 0 | 0 | 0 | 0,385% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ş | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.780% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ś | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,660% | 0 | 0 | 0 | 0 | 0 |
| š | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~ 0% | 0,688% |
| WL | 0 | 0 | 0,307% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ť | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,006% |
| º | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,455% | 0 | 0 |
| você | 0 | 0,058% | 0 | 0 | 0 | 0 | (0,166%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| você | 0 | 0 | 0 | 0,168% | 0,207% | 0 | 0,166% | 0 | 0 | 0 | 0 | 0 | 0,613% | 0 | 0,045% |
| você | ~ 0% | 0,060% | 0 | 0 | 0 | 0 | ~ 0% | ~ 0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| você | 0 | 0 | 0 | 0 | 0 | 0,520% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| você | ~ 0% | 0 | 0,995% | 0,012% | 0,026% | 0 | 0 | 1,854% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| você | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,204% |
| ý | 0 | 0 | 0 | ~ 0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,228% | 0 | 0,995% |
| ź | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,060% | 0 | 0 | 0 | 0 | 0 |
| ż | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,830% | 0 | 0 | 0 | 0 | 0 |
| ž | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~ 0% | 0,721% |
* Veja pontilhada e eu dotless .
A figura abaixo ilustra as distribuições de frequência das 26 letras latinas mais comuns em alguns idiomas. Todos esses idiomas usam um alfabeto semelhante de mais de 25 caracteres.
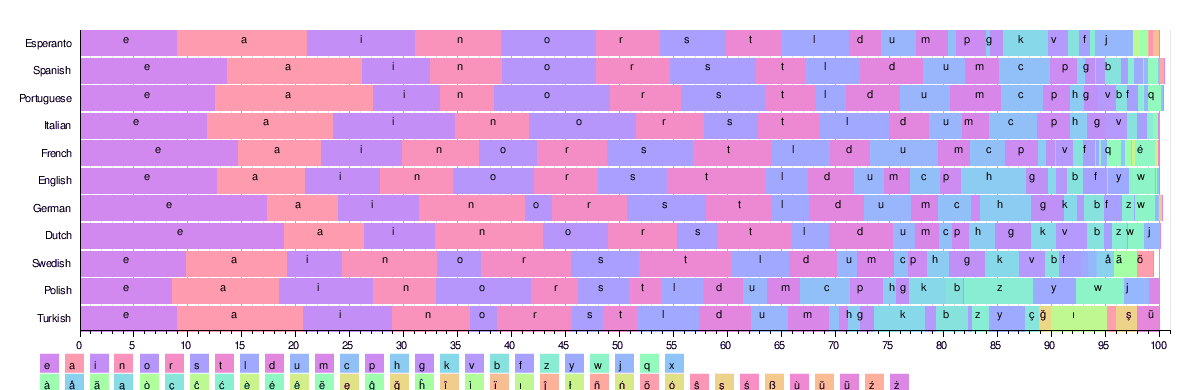
Com base nessas tabelas, os resultados equivalentes a ' etaoin shrdlu ' para cada idioma são os seguintes:
- Francês: 'esait nruol'; (Indo-europeu: itálico; tradicionalmente, 'esartinulop' é usado, em parte por sua facilidade de pronúncia)
- Espanhol: 'eaosr nidlt'; (Indo-europeu: itálico)
- Português: 'aeosr idmnt' (indo-europeu: itálico)
- Italiano: 'eaion lrtsc'; (Indo-europeu: itálico)
- Esperanto: 'aieon lsrtk' (linguagem artificial - léxico influenciado por línguas indo-europeias, romance, principalmente germânico)
- Alemão: 'enisr atdhu'; (Indo-europeu: germânico)
- Sueco: 'eanrt sildo'; (Indo-europeu: germânico)
- Turco: 'aeinr lkdım'; (Turco)
- Holandês: 'enati rodsl'; (Indo-europeu: germânico)
- Polonês: 'aioez nrwst'; (Indo-europeu: balto-eslavo)
- Dinamarquês: 'ernta idslo'; (Indo-europeu: germânico)
- Islandês: 'arnie stulð'; (Indo-europeu: germânico)
- Finlandês: 'ainte slouk'; (Uralic: Finnic)
- Tcheco: 'aeoni tvsrl'; (Indo-europeu: balto-eslavo)
Veja também
- Linguística de corpus
- RSTLNE ( Roda da Fortuna )
- Frequência de palavras em inglês
- Frequência de letras árabes
- Layout de teclado Dvorak
Notas explicativas
Referências
Citações
Referências gerais
Algumas tabelas úteis para frequências de letra única, digrama, trigrama, tetragrama e pentagrama com base em 20.000 palavras que levam em consideração combinações de comprimento de palavra e posição de letra para palavras de 3 a 7 letras. As referências são as seguintes:
- Mayzner, MS; Tresselt, ME; Wolin, BR (1965). "Tabelas de contagens de frequência de letra única e digrama para várias combinações de comprimento de palavra e posição de letra". Suplementos para monografias psiconômicas . 1 (2): 13–32. OCLC 639975358 .
- Mayzner, MS; Tresselt, ME; Wolin, BR (1965). "Tabelas de contagens de freqüência de trigrama para várias combinações de comprimento de palavra e posição de letra". Suplementos de monografias psiconômicas . 1 (3): 33–78.
- Mayzner, MS; Tresselt, ME; Wolin, BR (1965). "Tabelas de contagem de freqüência de tetragrama para várias combinações de comprimento de palavra e posição de letra". Suplementos para monografias psiconômicas . 1 (4): 79–143.
- Mayzner, MS; Tresselt, ME; Wolin, BR (1965). "Tabelas de contagem de freqüência de pentagrama para várias combinações de comprimento de palavra e posição de letra". Suplementos de monografias psiconômicas . 1 (5): 144–190.
links externos
- Lewand, Robert Edward. "Matemática criptográfica" . pages.central.edu. Arquivado do original em 2007-04-02.
- "Alguns exemplos de classificações de frequência de letras em alguns idiomas comuns" . www.bckelk.ukfsn.org.
- "Visualização de mapa de calor JavaScript mostrando frequências de letras de textos em diferentes layouts de teclado" . www.patrick-wied.at.
- Norvig, Peter. "Uma versão atualizada do trabalho de Mayzner usando o conjunto de dados Ngrams do Google books" . norvig.com.
- Frequência de letras —simia.net