
Árvore Radix - Radix tree

Na ciência da computação , uma árvore raiz (também trie raiz ou árvore de prefixo compacto ) é uma estrutura de dados que representa um trie otimizado para espaço (árvore de prefixo) em que cada nó que é o único filho é mesclado com seu pai. O resultado é que o número de filhos de cada nó interno é no máximo a raiz r da árvore raiz, onde r é um número inteiro positivo e uma potência x de 2, tendo x ≥ 1. Ao contrário das árvores regulares, as arestas podem ser rotuladas com sequências de elementos, bem como elementos individuais. Isso torna as árvores radix muito mais eficientes para conjuntos pequenos (especialmente se as strings forem longas) e para conjuntos de strings que compartilham prefixos longos.
Ao contrário das árvores regulares (onde chaves inteiras são comparadas em massa desde o seu início até o ponto de desigualdade), a chave em cada nó é comparada pedaço de bits por pedaço de bits, onde a quantidade de bits nesse pedaço em esse nó é a raiz r da raiz trie. Quando r é 2, o trie de raiz é binário (ou seja, compare a porção de 1 bit desse nó da chave), o que minimiza a dispersão às custas de maximizar a profundidade do trie - ou seja, maximizar até a fusão de cadeias de bits não divergentes no chave. Quando r é uma potência inteira de 2 com r ≥ 4, então o trie raiz é um trie r -ary, o que diminui a profundidade do trie raiz às custas da dispersão potencial.
Como uma otimização, os rótulos de borda podem ser armazenados em tamanho constante usando dois ponteiros para uma string (para o primeiro e o último elemento).
Observe que, embora os exemplos neste artigo mostrem strings como sequências de caracteres, o tipo dos elementos de string pode ser escolhido arbitrariamente; por exemplo, como um bit ou byte da representação de string ao usar codificações de caracteres multibyte ou Unicode .
Formulários
Árvores radix são úteis para construir matrizes associativas com chaves que podem ser expressas como strings. Eles encontram aplicação particular na área de roteamento IP , onde a capacidade de conter grandes intervalos de valores com algumas exceções é particularmente adequada para a organização hierárquica de endereços IP . Eles também são usados para índices invertidos de documentos de texto na recuperação de informações .
Operações
As árvores Radix suportam operações de inserção, exclusão e pesquisa. A inserção adiciona uma nova string ao teste enquanto tenta minimizar a quantidade de dados armazenados. A exclusão remove uma string do teste. As operações de pesquisa incluem (mas não estão necessariamente limitadas a) pesquisa exata, localizar predecessor, localizar sucessor e localizar todas as strings com um prefixo. Todas essas operações são O ( k ) onde k é o comprimento máximo de todas as strings no conjunto, onde o comprimento é medido na quantidade de bits igual à raiz do trie de raiz.
Olho para cima

A operação de pesquisa determina se uma string existe em um trie. A maioria das operações modifica essa abordagem de alguma forma para lidar com suas tarefas específicas. Por exemplo, o nó onde uma string termina pode ser importante. Esta operação é semelhante às tentativas, exceto que algumas arestas consomem vários elementos.
O pseudocódigo a seguir pressupõe que essas classes existam.
Borda
- Node targetNode
- etiqueta da string
Nó
- Array of Edges arestas
- function isLeaf ()
function lookup(string x)
{
// Begin at the root with no elements found
Node traverseNode := root;
int elementsFound := 0;
// Traverse until a leaf is found or it is not possible to continue
while (traverseNode != null && !traverseNode.isLeaf() && elementsFound < x.length)
{
// Get the next edge to explore based on the elements not yet found in x
Edge nextEdge := select edge from traverseNode.edges where edge.label is a prefix of x.suffix(elementsFound)
// x.suffix(elementsFound) returns the last (x.length - elementsFound) elements of x
// Was an edge found?
if (nextEdge != null)
{
// Set the next node to explore
traverseNode := nextEdge.targetNode;
// Increment elements found based on the label stored at the edge
elementsFound += nextEdge.label.length;
}
else
{
// Terminate loop
traverseNode := null;
}
}
// A match is found if we arrive at a leaf node and have used up exactly x.length elements
return (traverseNode != null && traverseNode.isLeaf() && elementsFound == x.length);
}
Inserção
Para inserir uma string, procuramos na árvore até que não possamos fazer mais nenhum progresso. Neste ponto, ou adicionamos uma nova aresta de saída rotulada com todos os elementos restantes na string de entrada, ou se já houver uma aresta de saída compartilhando um prefixo com a string de entrada restante, nós a dividimos em duas arestas (a primeira rotulada com o comum prefixo) e prossiga. Essa etapa de divisão garante que nenhum nó tenha mais filhos do que os elementos de string possíveis.
Vários casos de inserção são mostrados abaixo, embora possam existir mais. Observe que r simplesmente representa a raiz. Presume-se que as arestas podem ser rotuladas com strings vazias para terminar as strings quando necessário e que a raiz não tem nenhuma borda de entrada. (O algoritmo de pesquisa descrito acima não funcionará ao usar bordas de strings vazias.)
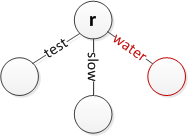
Insira 'água' na raiz
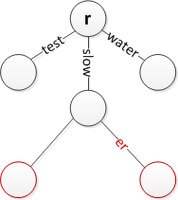
Insira 'mais lento' enquanto mantém 'lento'

Insira 'teste' que é um prefixo de 'testador'

Insira 'equipe' enquanto divide 'teste' e cria um novo rótulo de aresta 'st'
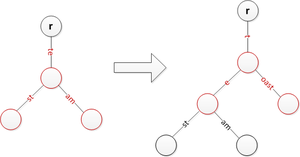
Insira 'toast' enquanto divide 'te' e move as cordas anteriores um nível abaixo





Eliminação
Para deletar uma string x de uma árvore, primeiro localizamos a folha que representa x. Então, assumindo que x existe, removemos o nó folha correspondente. Se o pai de nosso nó folha tiver apenas um outro filho, o rótulo de entrada desse filho será anexado ao rótulo de entrada do pai e o filho será removido.
Operações adicionais
- Encontre todas as strings com prefixo comum: Retorna uma matriz de strings que começam com o mesmo prefixo.
- Encontrar predecessor: localiza a maior string menor que uma determinada string, por ordem lexicográfica.
- Encontrar sucessor: localiza a menor string maior que uma determinada string, por ordem lexicográfica.
História
Donald R. Morrison descreveu pela primeira vez o que Donald Knuth , páginas 498-500 no Volume III de The Art of Computer Programming , chama de "árvores de Patricia" em 1968. Gernot Gwehenberger inventou e descreveu independentemente a estrutura de dados mais ou menos na mesma época. Árvores PATRICIA são árvores raiz com raiz igual a 2, o que significa que cada bit da chave é comparado individualmente e cada nó é um ramo de mão dupla (isto é, esquerda versus direita).
Comparação com outras estruturas de dados
(Nas comparações a seguir, presume-se que as chaves têm comprimento k e a estrutura de dados contém n membros.)
Ao contrário das árvores balanceadas , as árvores raiz permitem pesquisa, inserção e exclusão no tempo O ( k ) ao invés de O (log n ). Isso não parece uma vantagem, uma vez que normalmente k ≥ log n , mas em uma árvore balanceada cada comparação é uma comparação de string que requer O ( k ) tempo de pior caso, muitos dos quais são lentos na prática devido a longos prefixos comuns (em o caso em que as comparações começam no início da string). Em um teste, todas as comparações requerem tempo constante, mas são necessárias m comparações para pesquisar uma string de comprimento m . As árvores radix podem executar essas operações com menos comparações e requerem muito menos nós.
Árvores raiz também compartilham as desvantagens de tentativas, no entanto: como eles só podem ser aplicados a strings de elementos ou elementos com um mapeamento reversível de forma eficiente para strings, eles carecem da generalidade completa de árvores de pesquisa balanceadas, que se aplicam a qualquer tipo de dados com um total ordenando . Um mapeamento reversível para strings pode ser usado para produzir a ordem total necessária para árvores de pesquisa equilibradas, mas não o contrário. Isso também pode ser problemático se um tipo de dados fornecer apenas uma operação de comparação, mas não uma operação de (des) serialização .
É comum dizer que as tabelas de hash têm tempos esperados de inserção e exclusão O (1), mas isso só é verdade quando se considera o cálculo do hash da chave como uma operação de tempo constante. Quando o hash da chave é levado em consideração, as tabelas hash têm tempos esperados de inserção e exclusão O ( k ), mas podem demorar mais no pior caso, dependendo de como as colisões são tratadas. Árvores raiz têm pior caso de inserção e deleção de O ( k ). As operações de sucessor / predecessor de árvores raiz também não são implementadas por tabelas de hash.
Variantes
Uma extensão comum de árvores radix usa duas cores de nós, 'preto' e 'branco'. Para verificar se uma determinada string está armazenada na árvore, a pesquisa começa do topo e segue as bordas da string de entrada até que nenhum progresso possa ser feito. Se a string de pesquisa for consumida e o nó final for um nó preto, a pesquisa falhou; se for branco, a pesquisa foi bem-sucedida. Isso nos permite adicionar uma grande variedade de strings com um prefixo comum à árvore, usando nós brancos e, em seguida, remover um pequeno conjunto de "exceções" de maneira eficiente em termos de espaço, inserindo- os usando nós pretos.
O HAT-trie é uma estrutura de dados consciente do cache baseada em árvores radix que oferece armazenamento e recuperação de strings eficientes e iterações ordenadas. O desempenho, com respeito a tempo e espaço, é comparável ao hashtable consciente do cache . Veja as notas de implementação do teste HAT em [1]
Um teste PATRICIA é uma variante especial do teste raiz 2 (binário), no qual, em vez de armazenar explicitamente cada bit de cada chave, os nós armazenam apenas a posição do primeiro bit que diferencia duas subárvores. Durante o percurso, o algoritmo examina o bit indexado da chave de pesquisa e escolhe a subárvore esquerda ou direita conforme apropriado. Características notáveis do trie PATRICIA incluem que o trie requer apenas um nó a ser inserido para cada chave única armazenada, tornando o PATRICIA muito mais compacto do que um trie binário padrão. Além disso, como as chaves reais não são mais armazenadas explicitamente, é necessário realizar uma comparação completa de chaves no registro indexado para confirmar uma correspondência. A este respeito, PATRICIA tem uma certa semelhança com a indexação usando uma tabela hash.
A árvore raiz adaptativa é uma variante da árvore raiz que integra tamanhos de nós adaptativos à árvore raiz. Uma grande desvantagem das árvores radix usuais é o uso do espaço, porque ele usa um tamanho de nó constante em todos os níveis. A principal diferença entre a árvore raiz e a árvore raiz adaptativa é seu tamanho variável para cada nó com base no número de elementos filho, que cresce ao adicionar novas entradas. Conseqüentemente, a árvore raiz adaptativa leva a um melhor uso do espaço sem reduzir sua velocidade.
Uma prática comum é relaxar o critério de não permitir pais com apenas um filho em situações em que o pai representa uma chave válida no conjunto de dados. Esta variante da árvore raiz atinge uma eficiência de espaço maior do que aquela que só permite nós internos com pelo menos dois filhos.
Veja também
- Árvore de prefixo (também conhecida como Trie)
- Autômato de estado finito acíclico determinístico (DAFSA)
- Tentativas de pesquisa ternária
- Lixo de hash
- Autômatos finitos determinísticos
- Judy array
- Algoritmo de busca
- Hashing extensível
- Hash array mapeado trie
- Árvore de hash de prefixo
- Burstsort
- Algoritmo de Luleå
- Codificação Huffman
Referências
links externos
- Material de referência e pesquisa de algoritmos e estruturas de dados: PATRICIA , de Lloyd Allison, Monash University
- Patricia Tree , Dicionário NIST de Algoritmos e Estruturas de Dados
- Árvores de bits críticos , de Daniel J. Bernstein
- API Radix Tree no kernel do Linux , por Jonathan Corbet
- Kart (árvore raiz de alteração chave) , de Paul Jarc
- The Adaptive Radix Tree: ARTful Indexing for Main-Memory Databases , de Viktor Leis, Alfons Kemper, Thomas Neumann, Technical University of Munich
Implementações
- Implementação do FreeBSD , usado para paging, encaminhamento e outras coisas.
- Implementação do kernel do Linux , usado para o cache de página, entre outras coisas.
- A biblioteca GNU C ++ Standard tem uma implementação trie
- Implementação Java do Concurrent Radix Tree , por Niall Gallagher
- Implementação C # de uma árvore Radix
- Practical Algorithm Template Library , uma biblioteca C ++ em tentativas PATRICIA (VC ++> = 2003, GCC G ++ 3.x), por Roman S. Klyujkov
- Implementação da classe de modelo Patricia Trie C ++ , por Radu Gruian
- Implementação da biblioteca padrão Haskell "baseada em árvores patricia big-endian". Código - fonte navegável pela web .
- Implementação de Patricia Trie em Java , por Roger Kapsi e Sam Berlin
- Árvores de bits críticos bifurcadas do código C por Daniel J. Bernstein
- Implementação de Patricia Trie em C , em libcprops
- Patricia Trees: conjuntos e mapas eficientes sobre inteiros em OCaml , de Jean-Christophe Filliâtre
- Implementação de Radix DB (Patricia trie) em C , de GB Versiani
- Libart - Adaptive Radix Trees implementado em C , por Armon Dadgar com outros contribuidores (Open Source, licença BSD de 3 cláusulas)
- Implementação Nim de uma árvore de bits críticos
- rax , uma implementação de árvore radix em ANSI C por Salvatore Sanfilippo (o criador do REDIS )