
Análise exploratória de dados - Exploratory data analysis
| Parte de uma série de estatísticas |
| Visualização de dados |
|---|
| Dimensões principais |
| Figuras importantes |
| Tipos gráficos de informação |
| tópicos relacionados |
Em estatística , a análise exploratória de dados é uma abordagem de análise de conjuntos de dados para resumir suas características principais, geralmente usando gráficos estatísticos e outros métodos de visualização de dados . Um modelo estatístico pode ser usado ou não, mas principalmente EDA é para ver o que os dados podem nos dizer além da modelagem formal ou tarefa de teste de hipótese. A análise exploratória de dados foi promovida por John Tukey desde 1970 para encorajar os estatísticos a explorar os dados e, possivelmente, formular hipóteses que poderiam levar a novas coletas de dados e experimentos. O EDA é diferente da análise inicial de dados (IDA) , que se concentra mais especificamente na verificação das suposições necessárias para o ajuste do modelo e teste de hipóteses, e no tratamento de valores ausentes e nas transformações de variáveis conforme necessário. EDA abrange IDA.
Visão geral
Tukey definiu a análise de dados em 1961 como: "Procedimentos para analisar dados, técnicas para interpretar os resultados de tais procedimentos, formas de planejar a coleta de dados para tornar sua análise mais fácil, mais precisa ou mais precisa, e todo o maquinário e resultados de ( estatísticas matemáticas) que se aplicam à análise de dados. "
A defesa de EDA de Tukey encorajou o desenvolvimento de pacotes de computação estatística , especialmente S no Bell Labs . A linguagem de programação S inspirou os sistemas S-PLUS e R . Essa família de ambientes de computação estatística apresentou recursos de visualização dinâmica amplamente aprimorados, o que permitiu aos estatísticos identificar outliers , tendências e padrões em dados que mereciam um estudo mais aprofundado.
A EDA de Tukey estava relacionada a dois outros desenvolvimentos na teoria estatística : estatística robusta e estatística não paramétrica , ambas tentando reduzir a sensibilidade das inferências estatísticas a erros na formulação de modelos estatísticos . Tukey promoveu o uso de cinco resumos de números de dados numéricos - os dois extremos ( máximo e mínimo ), a mediana e os quartis - porque essas medianas e quartis, sendo funções da distribuição empírica, são definidas para todas as distribuições, ao contrário da média e desvio padrão ; além disso, os quartis e a mediana são mais robustos para distribuições enviesadas ou de cauda pesada do que os resumos tradicionais (a média e o desvio padrão). Os pacotes S , S-PLUS e R incluíam rotinas usando estatísticas de reamostragem , como Quenouille e Tukey's jackknife e Efron 's bootstrap , que são não paramétricas e robustas (para muitos problemas).
A análise exploratória de dados, estatísticas robustas, estatísticas não paramétricas e o desenvolvimento de linguagens de programação estatística facilitaram o trabalho dos estatísticos em problemas científicos e de engenharia. Esses problemas incluíam a fabricação de semicondutores e a compreensão das redes de comunicação, que preocupavam a Bell Labs. Esses desenvolvimentos estatísticos, todos defendidos por Tukey, foram projetados para complementar a teoria analítica de testar hipóteses estatísticas , particularmente a ênfase da tradição laplaciana em famílias exponenciais .
Desenvolvimento

John W. Tukey escreveu o livro Exploratory Data Analysis em 1977. Tukey sustentava que muita ênfase em estatística era colocada em testes de hipóteses estatísticas (análise de dados confirmatórios); mais ênfase precisava ser colocada no uso de dados para sugerir hipóteses a serem testadas. Em particular, ele sustentou que confundir os dois tipos de análises e empregá-los no mesmo conjunto de dados pode levar a um viés sistemático devido às questões inerentes ao teste de hipóteses sugeridas pelos dados .
Os objetivos da EDA são:
- Sugerir hipóteses sobre as causas dos fenômenos observados
- Avalie as suposições nas quais a inferência estatística será baseada
- Apoiar a seleção de ferramentas e técnicas estatísticas apropriadas
- Fornece uma base para mais coleta de dados por meio de pesquisas ou experimentos
Muitas técnicas de EDA foram adotadas na mineração de dados . Eles também estão sendo ensinados a jovens estudantes como uma forma de introduzi-los ao pensamento estatístico.
Técnicas e ferramentas
Existem várias ferramentas que são úteis para a EDA, mas a EDA é caracterizada mais pela atitude tomada do que por técnicas específicas.
As técnicas gráficas típicas usadas em EDA são:
- Box plot
- Histograma
- Gráfico multivariável
- Executar gráfico
- Diagrama de pareto
- Gráfico de dispersão
- Gráfico caule e folha
- Coordenadas paralelas
- Razão de probabilidade
- Perseguição de projeção direcionada
- Métodos de visualização baseados em glifos, como faces de PhenoPlot e Chernoff
- Métodos de projeção, como grand tour, tour guiado e tour manual
- Versões interativas desses gráficos
- Escala multidimensional
- Análise de componente principal (PCA)
- PCA Multilinear
- Redução de dimensionalidade não linear (NLDR)
- Iconografia de correlações
As técnicas quantitativas típicas são:
História
Muitas ideias de EDA podem ser rastreadas até autores anteriores, por exemplo:
- Francis Galton enfatizou estatísticas de pedidos e quantis .
- Arthur Lyon Bowley usou precursores do gráfico radical e resumo de cinco números (Bowley na verdade usou um " resumo de sete dígitos ", incluindo os extremos, decis e quartis , junto com a mediana - consulte seu Manual de Estatística Elementar (3ª ed., 1920 ), página 62 - ele define "o máximo e mínimo, mediana, quartis e dois decis" como as "sete posições").
- Andrew Ehrenberg articulou uma filosofia de redução de dados (veja seu livro de mesmo nome).
O curso da Open University Statistics in Society (MDST 242), pegou as idéias acima e as fundiu com o trabalho de Gottfried Noether , que introduziu a inferência estatística via sorteio e teste de mediana .
Exemplo
Os resultados do EDA são ortogonais à tarefa de análise primária. Para ilustrar, considere um exemplo de Cook et al. onde a tarefa de análise é encontrar as variáveis que melhor predizem a gorjeta que um jantar vai dar ao garçom. As variáveis disponíveis nos dados coletados para esta tarefa são: valor da gorjeta, fatura total, sexo do pagador, setor fumante / não fumante, horário do dia, dia da semana e tamanho da festa. A tarefa de análise primária é abordada ajustando-se um modelo de regressão em que a taxa de gorjeta é a variável de resposta. O modelo ajustado é
- ( taxa de gorjeta ) = 0,18 - 0,01 × (tamanho da festa)
que diz que à medida que o tamanho do jantar aumenta em uma pessoa (levando a uma conta mais alta), a taxa de gorjeta diminuirá em 1%.
No entanto, explorar os dados revela outras características interessantes não descritas por este modelo.
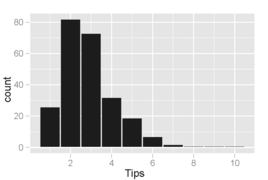
Histograma de valores de gorjeta em que as caixas cobrem incrementos de $ 1. A distribuição dos valores é inclinada para a direita e unimodal, como é comum nas distribuições de pequenas quantidades não negativas.

Histograma de valores de gorjeta em que as caixas cobrem incrementos de $ 0,10. Um fenômeno interessante é visível: picos ocorrem nas quantias de dólar inteiro e meio dólar, o que é causado pelos clientes escolhendo números redondos como gorjeta. Esse comportamento também é comum a outros tipos de compras, como gasolina.

Gráfico de dispersão de dicas vs. fatura. Os pontos abaixo da linha correspondem a gorjetas mais baixas do que o esperado (para aquele valor da fatura) e os pontos acima da linha são mais altos do que o esperado. Podemos esperar ver uma associação linear positiva e estreita, mas, em vez disso, ver uma variação que aumenta com a quantidade de gorjeta . Em particular, há mais pontos distantes da linha no canto inferior direito do que no canto superior esquerdo, indicando que mais clientes são muito baratos do que muito generosos.

Gráfico de dispersão de gorjetas vs. contas separadas por gênero do pagador e status da seção de fumantes. Festas de fumantes têm muito mais variação nas dicas que dão. Os homens tendem a pagar as (poucas) contas mais altas, e as mulheres não fumantes tendem a dar gorjetas muito consistentes (com três notáveis exceções mostradas na amostra).




O que é aprendido nos gráficos é diferente do que é ilustrado pelo modelo de regressão, embora o experimento não tenha sido projetado para investigar nenhuma dessas outras tendências. Os padrões encontrados ao explorar os dados sugerem hipóteses sobre inclinação que podem não ter sido antecipadas e que podem levar a experimentos de acompanhamento interessantes, onde as hipóteses são formalmente declaradas e testadas por meio da coleta de novos dados.
Programas
- JMP , um pacote EDA do SAS Institute .
- KNIME , Konstanz Information Miner - plataforma de exploração de dados de código aberto baseada no Eclipse.
- Minitab , um pacote de estatísticas gerais e EDA amplamente utilizado em ambientes industriais e corporativos.
- Orange , um pacote de software de mineração de dados e aprendizado de máquina de código aberto .
- Python , uma linguagem de programação de código aberto amplamente usada em mineração de dados e aprendizado de máquina.
- R , uma linguagem de programação de código aberto para computação estatística e gráficos. Junto com Python, uma das linguagens mais populares para ciência de dados.
- TinkerPlots um software EDA para alunos do ensino fundamental e médio.
- Weka, um pacote de mineração de dados de código aberto que inclui ferramentas de visualização e EDA, como a busca de projeção direcionada .
Veja também
- Quarteto de Anscombe , sobre a importância da exploração
- Dragagem de dados
- Análise preditiva
- Análise de dados estruturados (estatísticas)
- Análise de frequência de configuração
- Estatísticas descritivas
Referências
Bibliografia
- Andrienko, N & Andrienko, G (2005) Análise Exploratória de Dados Espaciais e Temporais. Uma abordagem sistemática . Springer. ISBN 3-540-25994-5
- Cook, D. e Swayne, DF (com A. Buja, D. Temple Lang, H. Hofmann, H. Wickham, M. Lawrence) (2007-12-12). Gráficos interativos e dinâmicos para análise de dados: com R e GGobi . Springer. ISBN 9780387717616.CS1 maint: vários nomes: lista de autores ( link )
- Hoaglin, DC; Mosteller, F & Tukey, John Wilder (Eds) (1985). Explorando tabelas de dados, tendências e formas . ISBN 978-0-471-09776-1.CS1 maint: vários nomes: lista de autores ( link ) CS1 maint: texto extra: lista de autores ( link )
- Hoaglin, DC; Mosteller, F & Tukey, John Wilder (Eds) (1983). Noções básicas sobre análise de dados robusta e exploratória . ISBN 978-0-471-09777-8.CS1 maint: vários nomes: lista de autores ( link ) CS1 maint: texto extra: lista de autores ( link )
- Inselberg, Alfred (2009). Coordenadas Paralelas: Geometria Visual Multidimensional e suas Aplicações . Londres, Nova York: Springer. ISBN 978-0-387-68628-8.
- Leinhardt, G., Leinhardt, S., Análise Exploratória de Dados: Novas Ferramentas para a Análise de Dados Empíricos , Revisão da Pesquisa em Educação, Vol. 8, 1980 (1980), pp. 85-157.
- Martinez, WL ; Martinez, AR & Solka, J. (2010). Análise Exploratória de Dados com MATLAB, segunda edição . Chapman & Hall / CRC. ISBN 9781439812204.
- Theus, M., Urbanek, S. (2008), Interactive Graphics for Data Analysis: Principles and Examples, CRC Press, Boca Raton, FL, ISBN 978-1-58488-594-8
- Tucker, L; MacCallum, R. (1993). Análise Fatorial Exploratória . [1] .
- Tukey, John Wilder (1977). Análise Exploratória de Dados . Addison-Wesley. ISBN 978-0-201-07616-5.
- Velleman, PF; Hoaglin, DC (1981). Aplicações, Fundamentos e Computação da Análise Exploratória de Dados . ISBN 978-0-87150-409-8.
- Young, FW Valero-Mora, P. e Friendly M. (2006) Visual Statistics: Seeing your data with Dynamic Interactive Graphics . Wiley ISBN 978-0-471-68160-1
- Jambu M. (1991) Exploratory and Multivariate Data Analysis . Academic Press ISBN 0123800900
- SHC DuToit, AGW Steyn, RH Stumpf (1986) Graphical Exploratory Data Analysis . Springer ISBN 978-1-4612-9371-2